本文内容参考 ChatGLM 团队发布在 B站 上的 GLM官方教程 以及 Github 上的 GLM 官方项目仓库内容编写
概要
2024/6/05 GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
| 配置项 | 配置 | |
| 硬件 | CPU | Intel® Core™ i5-12490F 3.00 GHz |
| 内存 | 64.0 GB DDR4 3200Mhz | |
| GPU | Nvidia GeForce RTX 4060 8GB | |
| 磁盘 | 2T PCIe4.0 NVMe M.2 SSD | |
| 操作系统 | Windows 11 专业版 23H2 | |
| 软件 | Python 3.12.3 | |
| CUDA 12.4 | ||
| PyTorch 2.4.0 | ||
| Flash Attention 2.6.3 | ||
模型部署
GLM-4-9B 系列模型对比
| 模型名 | 类型 | 特点 |
| GLM-4-9B | 基座模型 | 8K上下文,不能对话 |
| GLM-4-9B-Chat | 对话模型 | 128K上下文,具备工具调用能力 |
| GLM-4-9B-Chat-1M | 对话模型 | 1M上下文,具备工具调用能力,长文本模型 |
| GLM-4V-9B | VQA视觉模型 | 8K上下文,视觉对话 |
本文将使用 GLM-4-9B-Chat 进行部署实验
模型下载
GLM 团队已经将模型上传到 HuggingFace、魔搭,可以根据自己的网络环境选择合适的渠道:
魔搭(ModelScope):https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat
HuggingFace:https://huggingface.co/THUDM/glm-4-9b-chat
官方视频中推荐使用 git clone 方式下载模型,在 git bash 中进入合适的目录,输入上述下载页面提供的 git clone 命令即可下载。
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git
或
git clone https://huggingface.co/THUDM/glm-4-9b-chat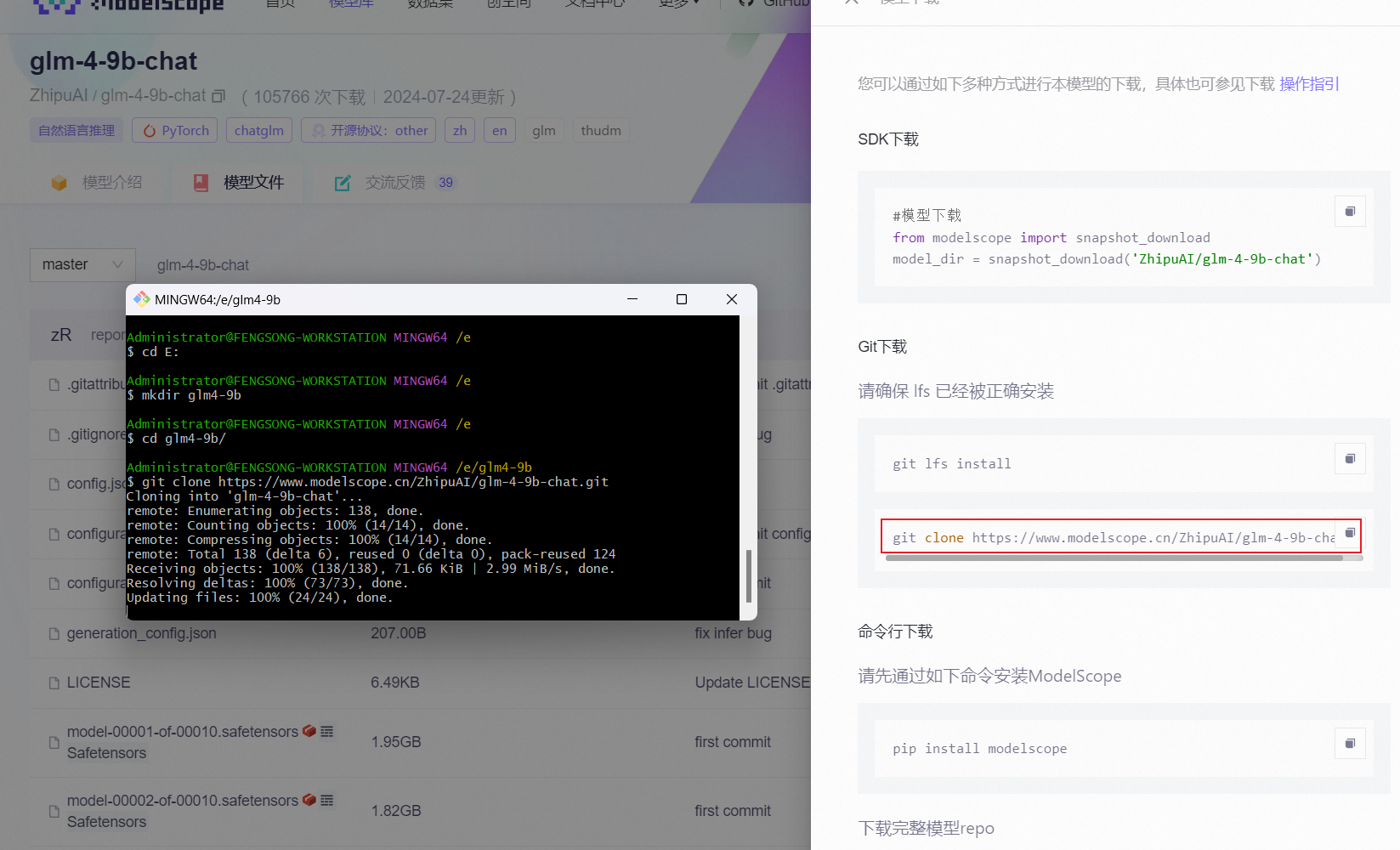
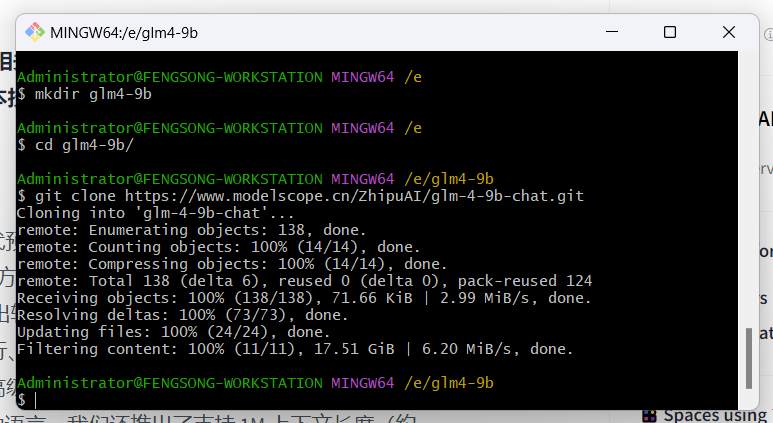
需要提醒的时,执行命令后,在单个文件下载过程中时没有进度提示的,只有文件下载完成时才会提醒 ‘done’ 。因为大模型的文件较大,如果卡住不动就是正在下载。如果不放心,可以在任务管理器中看一下 Git LFS 进程是否在占用网络。耐心等待后,在目录中就可以看到模型文件被逐个下载下来,bash 中也会有相应的更新:
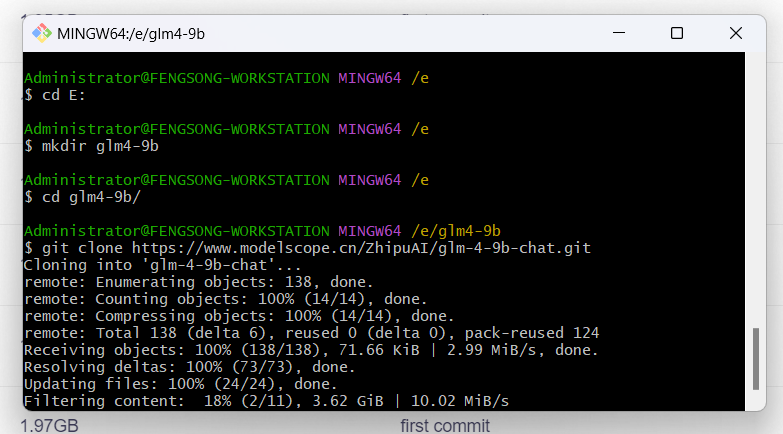
直到 Filtering content: 100% 表示全部文件已下载完毕,截止 2024 年 8 月,GLM-4-9B-Chat 仓库中的全部文件下载下来约占本地存储空间 35.0 GB。
硬件配置要求
根据 GLM 团队在其环境的测试,GLM-4 各模型推理时所需的显存如下表:
| 模型 | 精度 | 输入长度限制 | 显存占用 |
| GLM-4-9B-Chat | BF16 | 1,000 | 19 GB |
| 8,000 | 21 GB | ||
| 32,000 | 28 GB | ||
| 128,000 | 58 GB | ||
| INT4 | 1,000 | 8 GB | |
| 8,000 | 10 GB | ||
| 32,000 | 17 GB | ||
| GLM-4-9B-Chat-1M | BF16 | 200,000 | 75 GB |
| GLM-4V-9B | BF16 | 1,000 | 28 GB |
| 8,000 | 33 GB | ||
| INT4 | 1,000 | 10 GB | |
| 8,000 | 15 GB |
项目 Demo 部署
项目下载
进入 GLM-4 项目的 github 仓库:https://github.com/THUDM/GLM-4 ,下载 zip 或 git clone 到本地。至此,我们的本地分别有上一节中下载的模型,及刚刚下载的项目,两个目录:
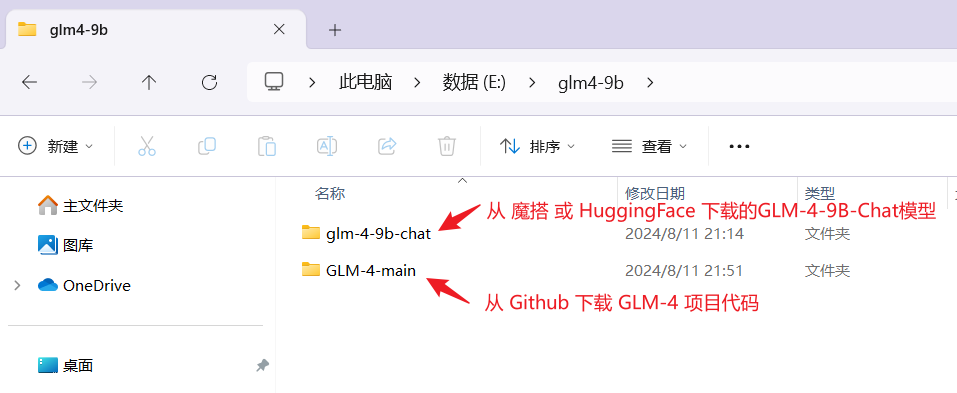
项目结构
官方开源的项目仓库中为开发者提供基础的 GLM-4-9B 的使用和开发代码:
/basic_demo 包含了:
- 使用 transformers 和 vLLM 后端的交互代码
- OpenAI API 后端交互代码
- Batch 推理代码
/composite_demo 包含了:
- GLM-4-9B-Chat 以及 GLM-4V-9B 开源模型的完整功能演示代码,包含了 All Tools 能力、长文档解读和多模态能力的展示。
/fintune_demo 包含了:
- PEFT (LORA, P-Tuning) 微调代码
- SFT 微调代码
这里,我们将使用 basic_demo 目录中提供的代码来运行官方 demo。
依赖环境部署
确保你已经安装 python,推荐使用 conda,在 conda 命令行中进入 basic_demo 项目目录,创建虚拟环境:
conda create -n glm-4-web-demo python=3.12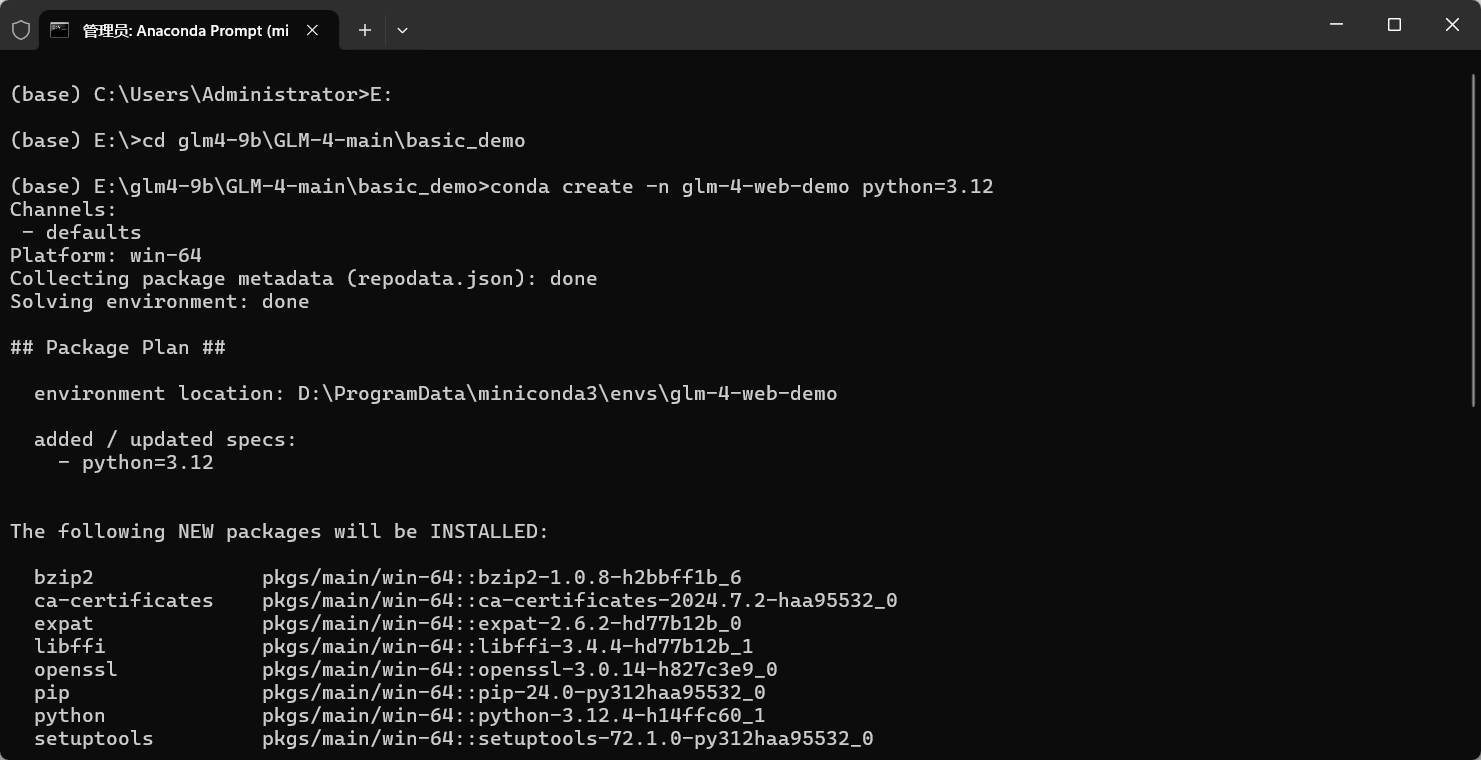
进入虚拟环境:
conda activate glm-4-web-demo
pip 安装所需依赖:
pip install -r requirements.txt
如果需要微调模型,还需安装 peft。如果不需要也可以将代码中的 import peft 注释掉。
pip install peft另外,还应注意,截止2024年8月11日,使用最新版的 transformers==4.44.0 会报错,需要安装 4.42.4。
8月12日,官方已更新代码,支持 4.44.0。
通过 CLI 对话
尽管可以使用 CPU 进行推理,但是速度极慢。本次实验我们使用 GPU 推理,首先需要确保本地已安装 CUDA。确保在 python 中可以通过 pytorch 使用 cuda,在 Python 命令行中执行如下命令,若返回 True 则正常:
>> import torch
>> torch.cuda.is_available()确保 CUDA 可以正常使用后,打开项目目录中的 trans_cli_demo.py ,这个文件是使用 Transformers 作为后端的 CLI Demo,允许用户通过命令行与模型进行指令交互。
修改以下代码,指定 torch 的计算设备为 gpu(若可用):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")修改以下代码,指定模型的路径:
MODEL_PATH = os.environ.get('MODEL_PATH', r'E:\glm4-9b\glm-4-9b-chat')修改以下代码,使用 BF16 精度并量化至 INT4 进行推理:
model = AutoModel.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
attn_implementation="flash_attention_2", #如果你没有安装flash attention,可以把这行注释掉
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(load_in_4bit=True),
low_cpu_mem_usage=True
).eval()此时,运行 trans_cli_demo.py ,由于配置了 torch_dtype=torch.bfloat16 ,模型的权重首先会以 BF16 精度加载到内存中。BF16 可以在保持较高精度的同时减少内存占用。当模型在内存中就绪后,由于我们设置了 device 为 cuda ,如果有足够的显存来容纳整个模型,模型就会被加载到显存中。如果显存不足,正常来说则会报错,但我们可以使用量化等技术来减少显存占用。这里我们配置了 quantization_config=BitsAndBytesConfig(load_in_4bit=True) 将权重量化至 INT4 精度,从而显著减少显存占用,得以将模型加载到 8G 以内的显存中。
等待模型加载完毕(在我的环境大概20多秒),就可以通过命令行与模型进行交互:
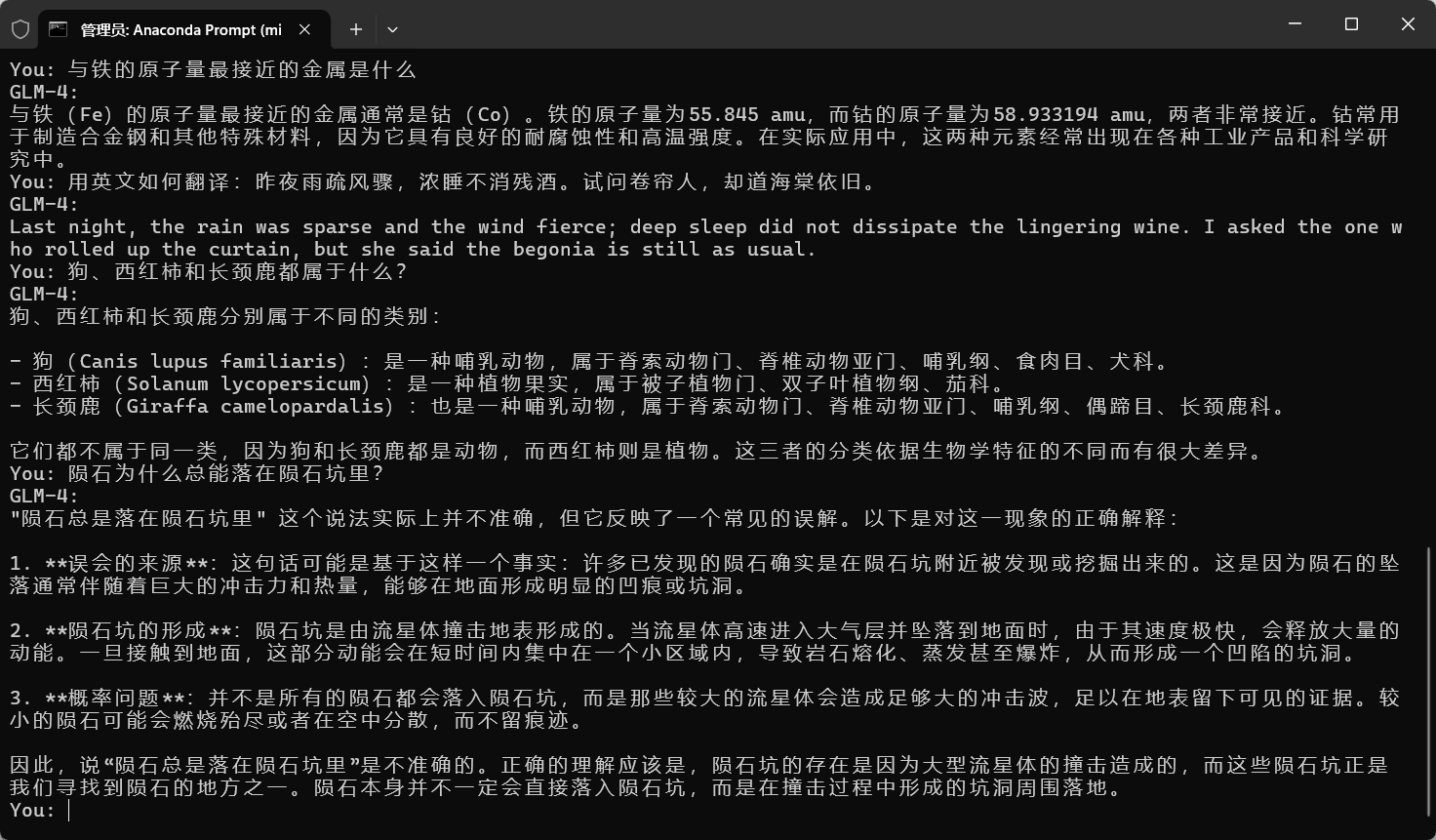
我们尝试问一些问题,GLM 将给出回答:
搭建 Web 服务
打开项目目录中的 trans_web_demo.py ,这个文件是使用 Transformers 作为后端的 Web Demo,使用 Gradio 创建了一个可交互的 Web Chat 界面。
与 CLI Demo 一样,修改代码,指定模型路径,使用 INT4 量化。此外,可以修改最后一行的地址和端口号:
demo.launch(server_name="127.0.0.1", server_port=8001, inbrowser=True, share=True)运行 trans_web_demo.py ,等待模型加载完毕(在我的环境大概30多秒),将提供一个本地 URL 和一个公网 URL (由 Gradio 提供的反向代理实现公网访问):
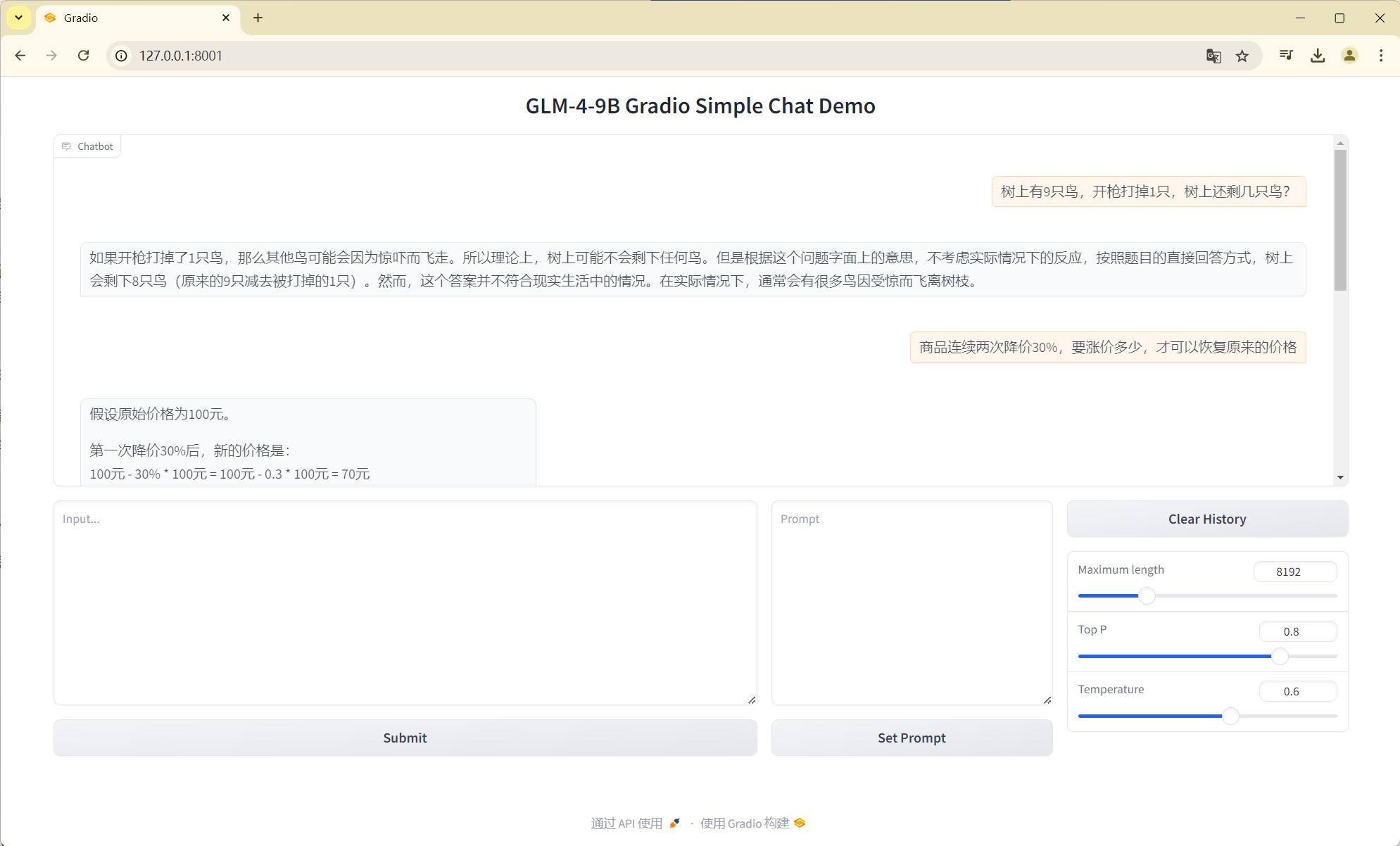
我们可以访问本地 URL 来使用 Web Chat 界面:
我们尝试问一些问题,GLM 将给出回答: